こんにちわ。arincoです。本日は、RNAからタンパク質へと翻訳が行われる時にどうやって開始してるの?という所を調べてみました。翻訳効率(翻訳のされ方)は、主に開始段階で調節されているそうです。
果たして、翻訳開始時におけるmRNAとtRNAとリボソームの関係ってどうなってるのでしょうか。
ぽちっと、よろしく御願いします。
 [1]
[1]
![]() [2]
[2]
 [3]
[3]
それでは、見ていきましょう。
mRNAの翻訳はAUGコドンから始まり、これには特定のtRNAが必要になります。この開始tRNAは、必ずメチオニンを運ぶので、タンパク合成が始まる側の最初のアミノ酸は必ずメチオニンになります。
ただし通常は、この開始メチオニンは、タンパク質酵素(プロテアーゼ)が除去してしまう為最後まで残りません。
真核生物において、メチオニンを結合している開始tRNAは、まず開始因子(「eIF」と呼ばれるタンパク質)と共に40Sリボソーム小サブユニットに結合します。この時、接着剤としてGTPが利用されています。
続いて、このtRNAを持ったリボソームの小サブユニットがmRNAの5’構造と呼ばれる場所と、それに結合しているたんぱく質(eIF-4E、eIF-4G)を目印として、mRNA分子の5’末端(一方の端っこ)に結合し、mRNAに沿って5’⇒3’(一端⇒他端)へ移動して、開始コドンであるAUGを探します。
この移動には、ATPを利用した開始因子が手助けをします。
基本的には、mRNAの殆どは最初に出会ったAUGから翻訳を開始します。最初のAUGに出会うと、小サブユニットに結合していた開始因子の一部が遊離し、その空いた場所に大サブユニットが結合hしてリボソームが完成します。
真核生物のmRNAでは、開始部位の周辺の塩基がAUGを探す際の認識効率を左右しています。この認識部位がコンセンサス配置(複数の塩基配列またはアミノ酸配列で共通性(完全に一致している必要は無い)の見られる配列)とあまりにも違うと、リボソームの小サブユニットが最初のAUGコドンを通りすぎ、2番目や3番目のAUGに行ってしまう事があります。
この事は「走査の見直し」と呼ばれますが、細胞はこの現象をさかんに利用して、同じmRNA分子からN末端の異なる2種類以上のタンパク質を作り出します。
一方、細菌は、翻訳開始コドンであるAUGの数塩基上流に「リボソーム結合配列」と呼ばれる特殊は塩基配列が存在しており、この配列が、リボソームの小サブユニットのrRNAと塩基対を形成して、これを開始コドンに誘導します。
従って、mRNAの中程にある開始コドンでも、その数塩基上流に「リボソーム結合配列」と呼ばれる配列がありさえすれば直接結合できます。
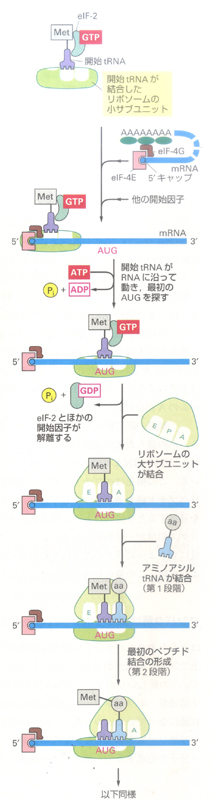
以上、今回の気づきは、リボソームがmRNAよりもまずはtRNAと結合するという事です。今まではまずmRNAとリボソームとして結合して、そ後にtRNAがやってくると思っていました。
また、細菌では、開始コドンの読み取りにRNAの塩基対方式を利用しているのが興味深いですね。もっと初期には、単純に塩基対の
パターンで触媒反応等も行われていた可能性もあるのかもしれませんね。
参考:細胞生物学 第4版